

I’m a fan of personal projects. Throughout the years, I have had the pleasure of writing multiple database-related blogs/GitHub projects. Now, I’ve decided I want one project to rule them all!
I’ve implemented my database in Golang and decided to share my knowledge by writing a blog post describing all the steps. This post is quite long, so I originally it was meant to be a 7 parts series. Eventually, I decided to keep it into one long blog post split into 7 original parts. This way, you stop and quickly come back to each chapter.
The database is intentionally simple and minimal, so the most important features will fit in but still make the code short.
The code is in Go, but it’s not complicated, and programmers unfamiliar with it can understand it. If you do know Golang, I encourage you to work along!
The entire codebase is on GitHub, and there are also around 50 tests to run when you’re done. In a second repo, the code is split into the 7 logical parts, each in a different folder.
We will create a simple NoSQL database in Go. I’ll present the concepts of databases and how to use them to create a NoSQL key/value database from scratch in Go. We will answer questions such as:
- What is NoSQL?
- How to store data on disk?
- The difference between disk-based and in-memory databases
- How are indexes made?
- What is ACID, and how do transactions work?
- How are databases designed for optimal performance?
The first part will start with an overview of the concepts we will use in our database and then implement a basic mechanism for writing to the disk.
SQL vs NoSQL
Databases fall into different categories. Those that are relevant to us are Relational databases (SQL), key-value store, and document store (Those are considered NoSQL). The most noticeable difference is the data model used by the database.
Relational databases organize data into tables (or “relations”) of columns and rows, with a unique key identifying each row. The rows represent instances of an entity (such as a “shop” for example), and the columns represent values attributed to that instance (such as “income” or “expanses”).
In relational databases, business logic may spread across the database. In other words, parts of a single object may appear in different tables across the database. We may have different tables for income and expenses, so to retrieve the entire shop entity from the database, we would have to query both tables.
Key-value and document stores are different. All information of a single entity is saved collectively in collections/buckets. Taking the example from earlier, a shop entity contains both income and expenses in a single instance and resides inside the shops collection.
Document stores are a subclass of key-value stores. The data is considered inherently opaque to the database in a key-value store, whereas a document-oriented system relies on the document’s internal structure.
For example, in a document store, it’s possible to query all shops by an internal field such as incomes, whereas key-value could fetch shops only by their id.

Those are the basic differences, though, in practice, there are more database types and more reasons to prefer one over another.
Our database will be a key-value store (not a document store) as its implementation is the most straightforward.
Disk-Based Storage
Databases organize their data (collections, documents …) in database pages. Pages are the smallest data unit exchanged by the database and the disk. It’s convenient to have a unit of work of fixed size. Also, it makes sense to put related data in proximity so it can be fetched all at once.
Database pages are stored contiguously on the disk to minimize disk seeks. Continuing our earlier example, consider a collection of 8 shops, where a single page is occupied by 2 shops. On the disk, it’ll look like the following:
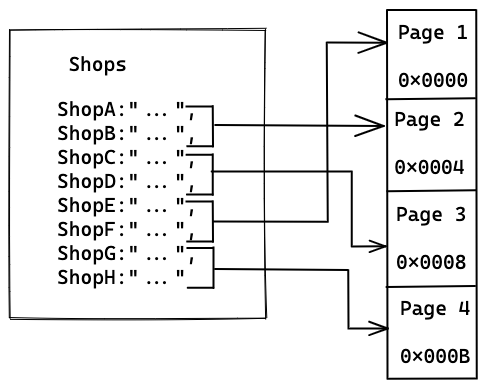
MySQL has a default page size of 16Kb, Postgres page size is 8Kb, and Apache Derby has a page size of 4Kb.
Bigger page sizes lead to better performance, but they risk having torn pages. A scenario where the system crashes in the middle of writing multiple database pages of a single write transaction.
Those factors are considered when choosing the page size in a real-life database. Those considerations are irrelevant to our database, so we will arbitrarily choose the size of our database pages to be 4KB.
