
I present what I belive is a unique index for indexing and searching source code. It copies ideas from Bing bitfunnel implementation to create a very fast, memory efficient trigram index over source code.
- searchcode.com is now using a custom built index written by yours truly
- It indexes 180-200 million documents and 75 billions lines of code
- The index works using bloom filters sharded by unique document trigrams
- It borrows some of the core ideas of bitfunnel used in microsoft’s bing
- The use of trigrams inside a bloom filter search is as far as I can tell unique
- It lowered the index search times from many seconds to ~40ms across searchcode
- End user searches still take around 300 ms to process though
- It also improved search relevance and reliability
- Architecture wise things became simpler, as the new index sits on a single machine not four
- It uses caddy as the reverse proxy and redis as a level 2 cache
- The index sits entirely in memory on a 16 core 5950x CPU and 128 GB RAM machine
- It currently processes close to a million searches every day
- I also gave the site a new look and feel which is much better than what it looked like previously
- I had an absolute blast learning and building it
What Happened?
On Monday 21st November 2022 I updated the DNS entries for searchcode to point at the new searchcode server running a custom implemented index, ending the reliance on sphinx/manticore in order to power searches. Since being released I have observed it run over 1 million searches a day with a rolling average runtime of ~40 ms for replacement index.
Sometime during the 2020 lock downs when I commented on the company slack that I should build my own custom index for searchcode. A few responded encouragingly that if anyone can do it it was me. While I appreciated their confidence I didn’t do anything until hiking with a mate sometime in 2021 where after a few beers at the end of the day I brimming with confidence laid out my plan of attack.
I had felt like a fraud for a while. I get a lot of questions about indexing code and my answer has always been that I use sphinx search. Recently that has changed, as I moved over to its forked version manticore search. Manticore is an excellent successor to sphinx and I really do recommend it.
However, using the above is me outsourcing the core functionality of searchcode to a third party, and I strongly believe you shouldn’t outsource your core competency. So I thought I should really try to do this myself. Besides, I knew I would really enjoy this process and so a few days later I started work.
The result of my effort can be viewed at searchcode.com and looks like the below.
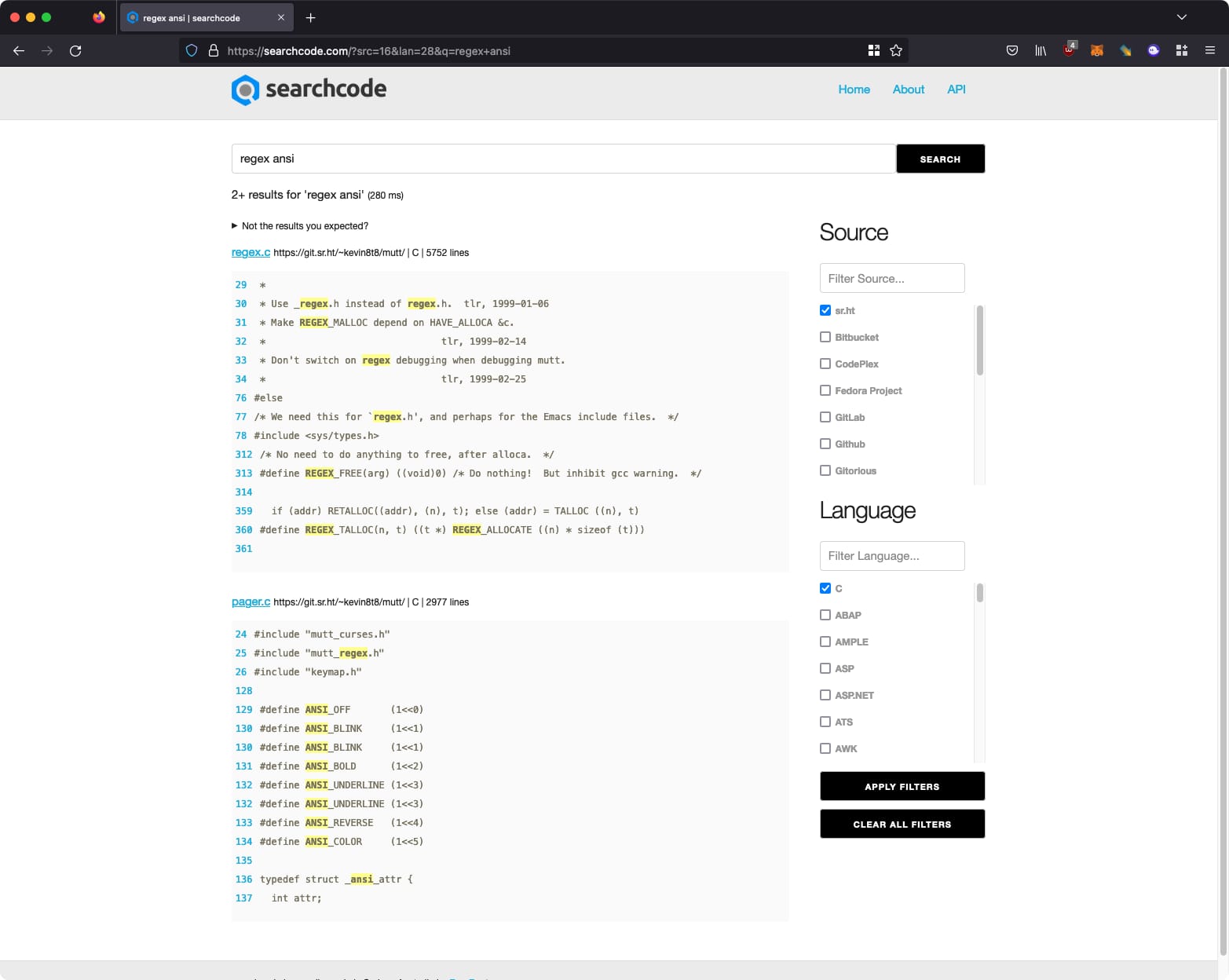
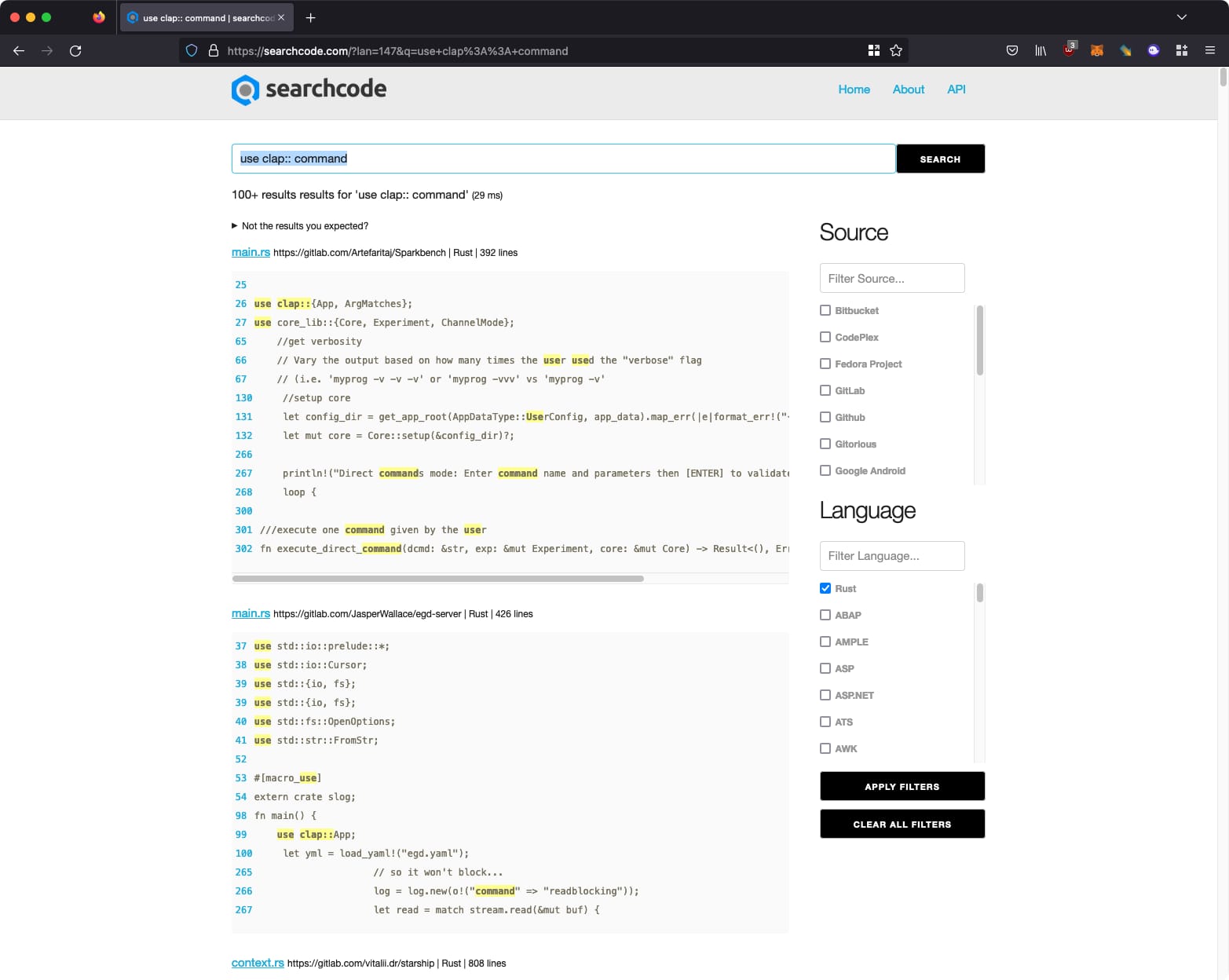
A little over a year’s worth of effort and I can now talk/write about it. I consider it the pinnacle of my development career to date, and I am very proud of my achievement. Feel free to read further if you would like to learn how I did it, what I was thinking etc… What follows is a collection of my development thoughts and ideas.
Development Thoughts
What follows are my thoughts I kept as I implemented things. Included so I have something to look back on, and perhaps someone will find it useful. It might be a bit disjointed as a lot of it was written as I was building things.
The Problem with Indexing Source Code
So why even build your own index? Why would anyone consider doing this when so many projects can do this for you. Off the top of my head we have code available for lucene, sphinx, solr, elasticsearch, manticore, xaipan, gigablast, bleve, bludge, mg4j, mnoGoSearch… you get the idea. There are a lot of them out there. Most of them however are focused on text and not source code, and the difference when it comes to search is larger than you might expect.
It’s also worth noting that the really large scale engines such as Bing and Google have their own indexing engines. Partly because it gives you the ability to wring more performance out of the system since you know where you can cut corners or save space, assuming you have the skill or knowledge.
I guess the saying “the thing about reinventing the wheel is you can get a round one” applies here. By implementing my own solution I could ensure I get something that works within the bounds of what I need.
